
About me
I am a Ph.D. candidate in Computer Science at the CVML Group, National University of Singapore (NUS), advised by Prof. Angela Yao. I am also a research intern at Taobao3D, Alibaba, working on large-scale 3D generative models.
My research focuses on controllable 3D generation and editing. I am particularly interested in how multimodal guidance and diffusion models can preserve reliable input evidence while completing, refining, and controlling ambiguous or missing 3D information.
I received my Master of Computing degree from NUS, where I further developed my research interests in AI and computer vision. Before that, I studied Information Management and Information Systems at the Beijing Institute of Technology (BIT), where I built a foundation in computing, systems, and problem-solving.
Publications
RelaxFlow: Text-Driven Amodal 3D Generation
Jiayin Zhu, Guoji Fu, Xiaolu Liu, Qiyuan He, Yicong Li, Angela Yao
International Conference on Machine Learning (ICML), 2026. Spotlight, top 2.2%.

Interp3D: Correspondence-Aware Interpolation for Generative Textured 3D Morphing
Xiaolu Liu, Yicong Li, Qiyuan He, Jiayin Zhu, Wei Ji, Angela Yao, Jianke Zhu
The Fourteenth International Conference on Learning Representations (ICLR), 2026.
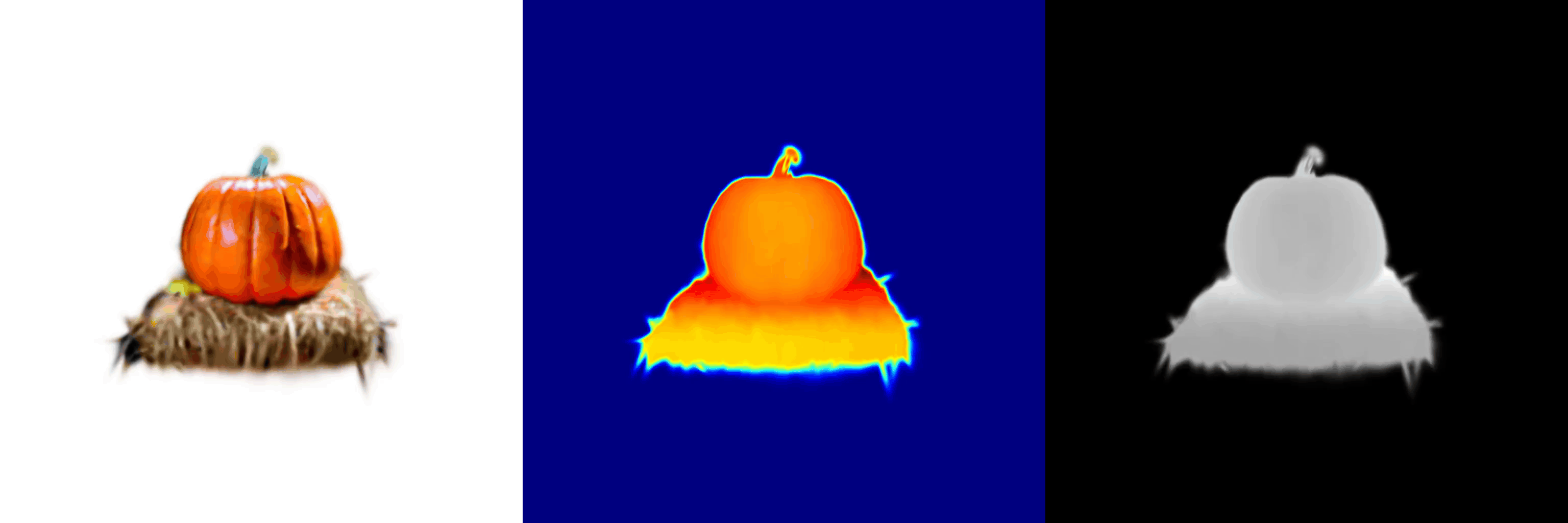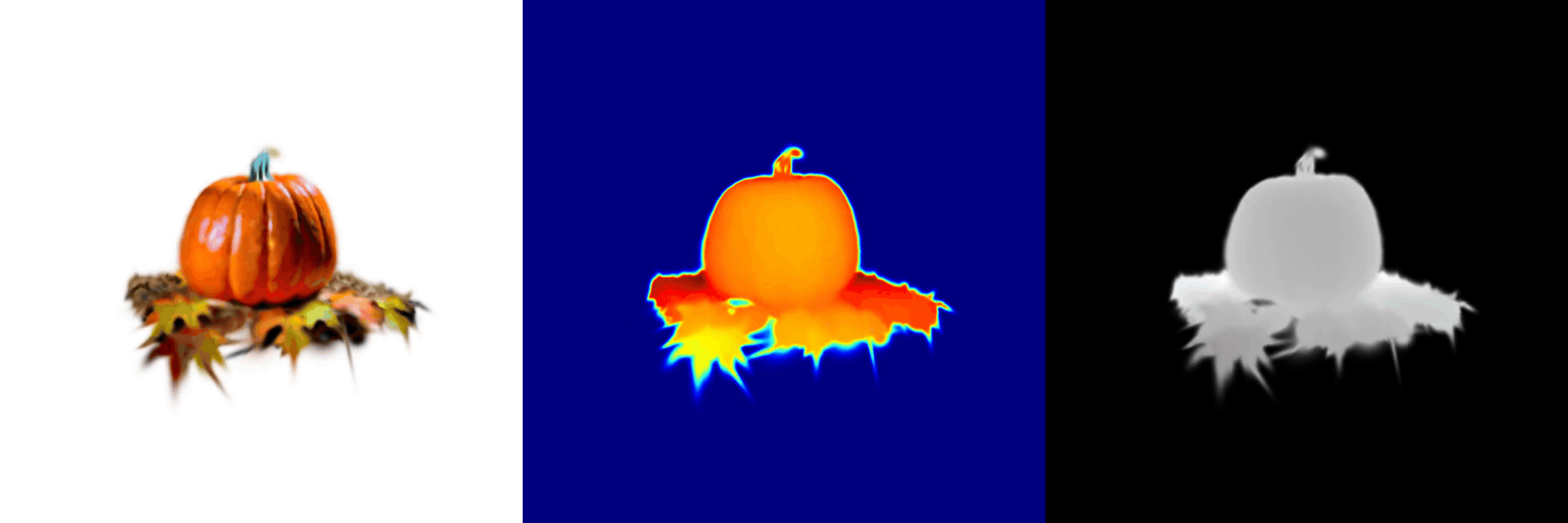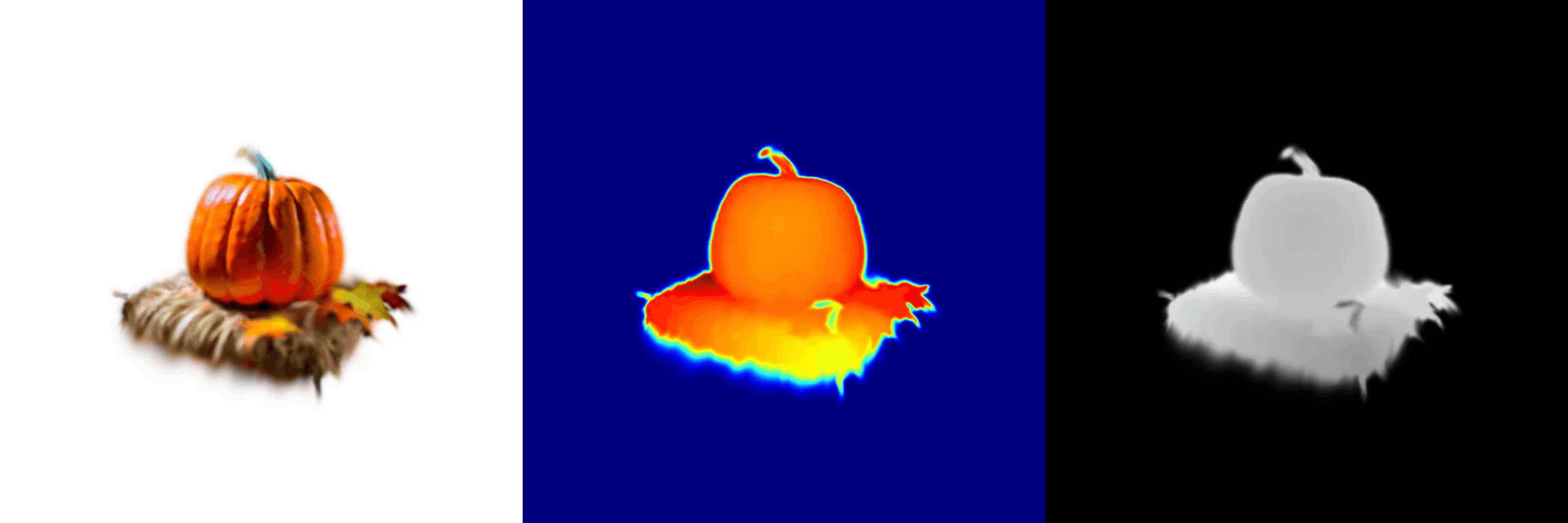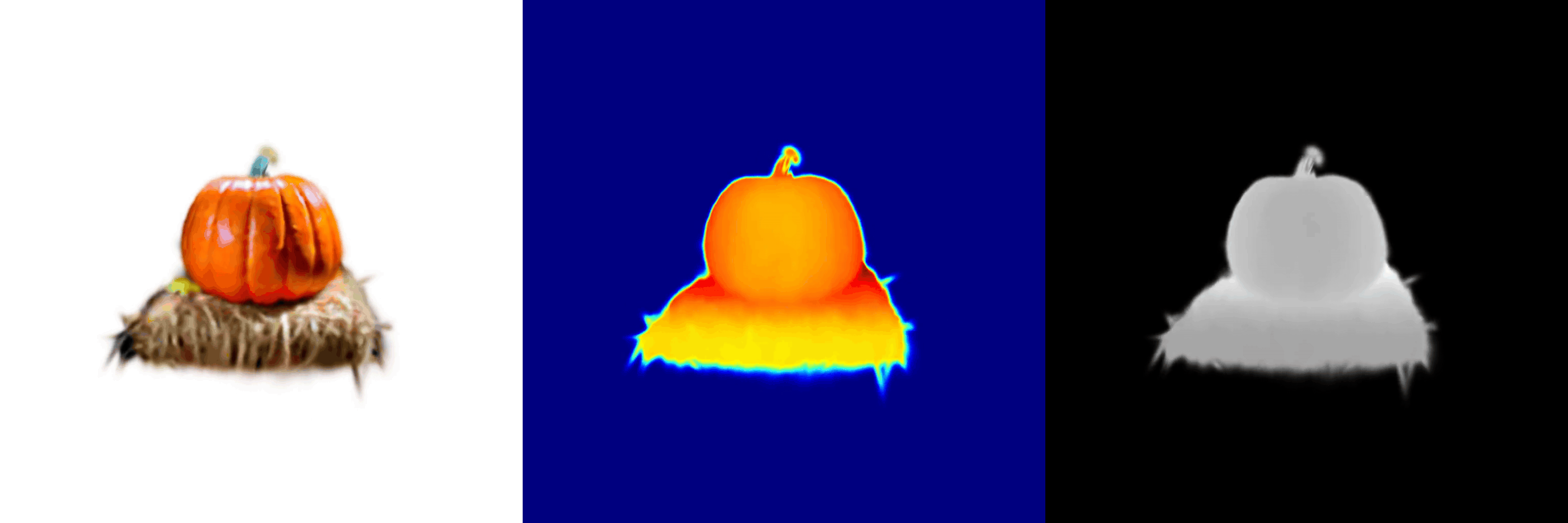
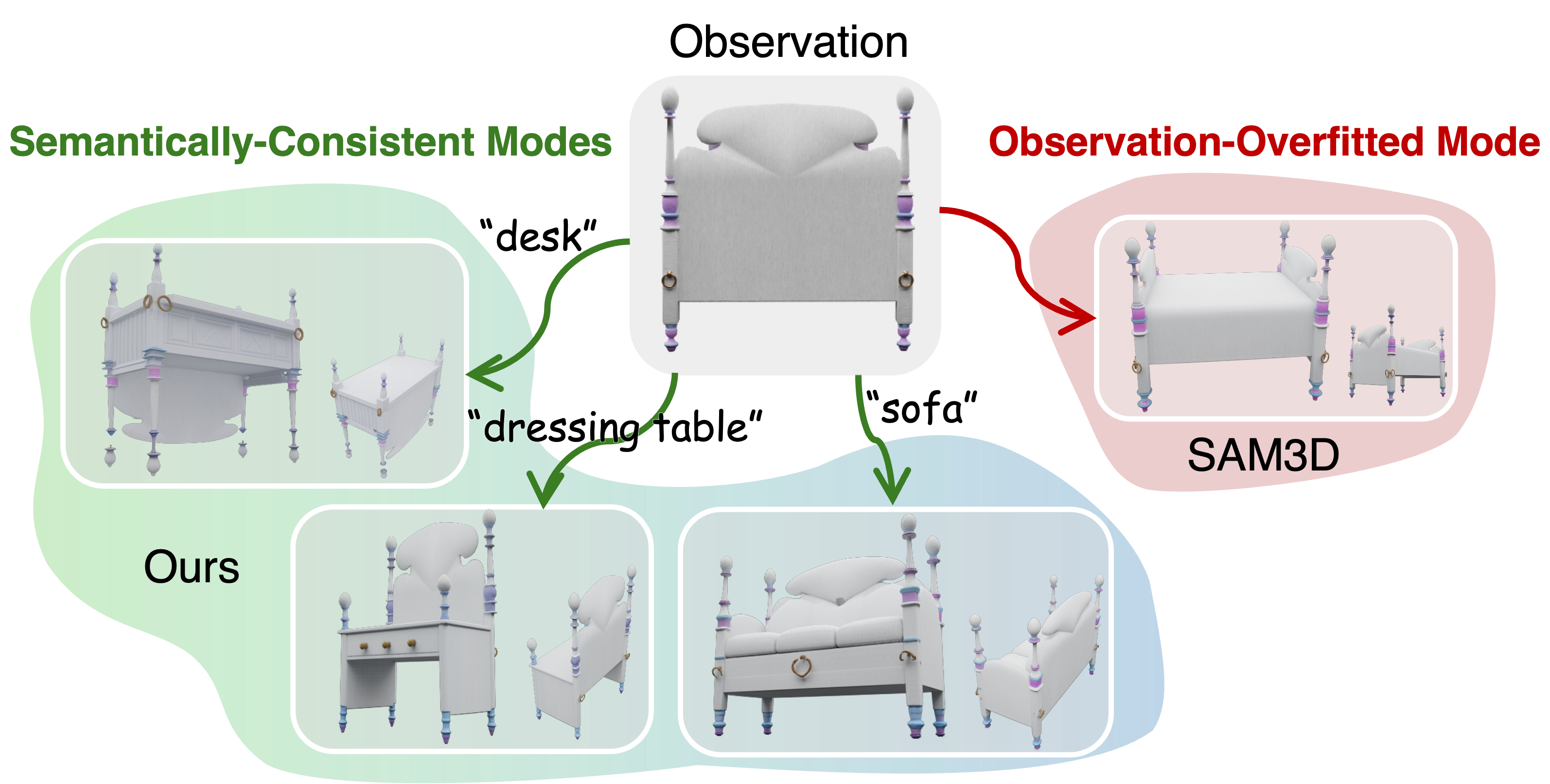
AnchorDS: Anchoring Dynamic Sources for Semantically Consistent Text-to-3D Generation
Jiayin Zhu, Linlin Yang, Yicong Li, Angela Yao
The 40th Annual AAAI Conference on Artificial Intelligence, 2026.

InstructHumans: Editing Animatable 3D Human Textures with Instructions
Jiayin Zhu, Linlin Yang, Angela Yao
IEEE Transactions on Multimedia (TMM), 2026.

3D Magic Mirror: Clothing Reconstruction from a Single Image via a Causal Perspective
Zhedong Zheng, Jiayin Zhu, Wei Ji, Yi Yang, Tat-Seng Chua
npj Artificial Intelligence, 2026.
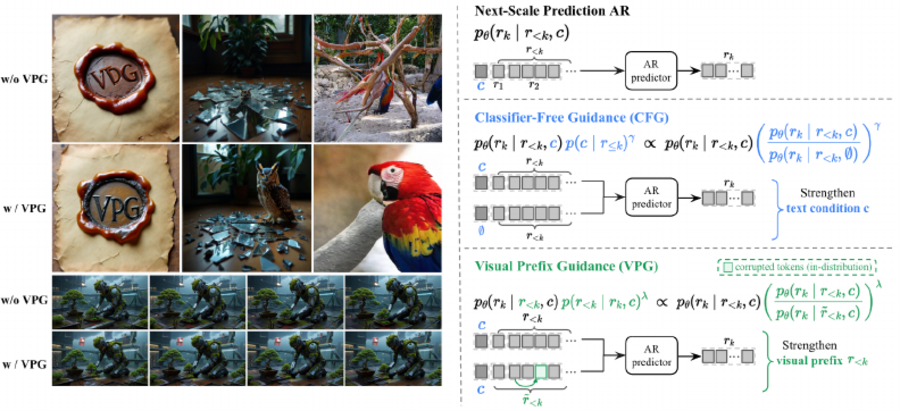
VPG: Visual Prefix Guidance for Autoregressive Image and Video Generation
Xinyao Liao, Qiyuan He, Yicong Li, Jiayin Zhu, Xiaoye Qu, Wei Wei, Angela Yao
arXiv preprint, 2026.

HiFiHR: Enhancing 3D Hand Reconstruction from a Single Image via High-Fidelity Texture
Jiayin Zhu, Zhuoran Zhao, Linlin Yang, Angela Yao
German Conference on Pattern Recognition (GCPR), 2023.
Services
- Teaching Asistant
- CS2100 Computer Organisation in Sem 1 AY2023/2024
- CS4243 Computer Vision and Pattern Recognition in Sem 2 AY2023/2024
- CS4243 Computer Vision and Pattern Recognition in Sem 2 AY2025/2026
- Reviewer: NeurIPS, ECCV, AAAI, ICLR, CVPR, ICML
Honors
- ICML Gold Reviewer Award, 2026
- Research Achievement Award, NUS, 2025
- Finalist (1%), Interdisciplinary Contest in Modeling, COMAP MCM/ICM, 2020
- Dean’s Academic Scholarship, BIT, 2020
Others
Rate my coding activity (?)

Rate my coding activity
0 think it's productive, 0 suggest more coding